Why you shouldn't store large files in Git
Last week, we shipped file-syncing for Moonglow, probably our most-requested feature. To design it, I spent a decent amount of time talking to ML researchers about what data they were syncing, how and why.
I was pretty surprised to learn how many people (ab)used git to transfer files between local and remote servers. This happened because many people needed to get sample images or videos over to their remote server, or send large json or csv files back so they could inspect them. And I can see using git would seem reasonable - there happened to be a git repo conveniently lying around, so why not use it?
But many of these files were huge. Some were up to 500 MB! As a software engineer, I had a vague disapproving feeling about all of this. But when I thought about it, I realized that I didn't couldn't actually explain why. I'd just knew that for years, people would frown and make sad faces if I committed large files to shared repos. So I never did it.
But I wanted to be able to explain what was going on, so I went did some digging. I quickly realized that it's fairly intuitive why pushing large binary blobs to git is bad.
It’s because git stores histories, and it lets everybody who uses that repository roll back to any other version of that repository at any point. Which means that it needs to be able to store enough information to restore the state of any branch at any moment. And to do that, it needs to store a copy of every file that's ever been committed.
Concretely, what this means is that if you push a 100MB file to your git repo, everybody else who ever clones that repo will also have to download your 100MB file and store on disk/in their git repo for the rest of eternity. This is true even if you immediately delete it in the next commit! It just sticks around forever, as unwanted dead weight.
But, this didn't satisfy my curiosity. It was a great high-level explanation, but I wanted to understand what was going on, one level deeper.
The Git object model
To understand exactly what's going on, it helps to understand how git works. There are 3 data structures in git: blobs, trees and commits.
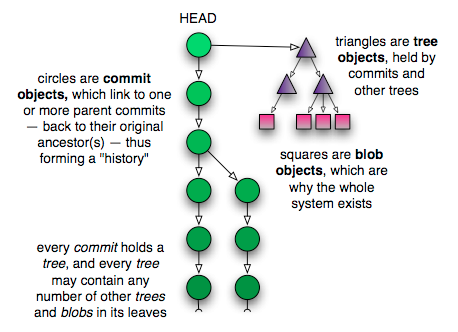
Blobs are individual files, stored in your .git/objects directory (which git calls the 'object database'). They’re not stored by filename, but instead by hash. What this means is that if you have two files named “text1.txt” and “text2.txt”, but they both contain the word “hello”, then you’ll only have one entry in the database: “hello”.
A fun and counterintuitive fact about blobs is that if you have one file, but you update it, git will store two blobs: one for the old version of the file and one for the new version of the file. And these aren’t diffs or deltas: git hashes and stores the entire file contents of the two file versions.
(This isn’t as horrifically inefficient as it seems, because Git does some compression along the way. You can read more about it by googling 'packfiles'.)
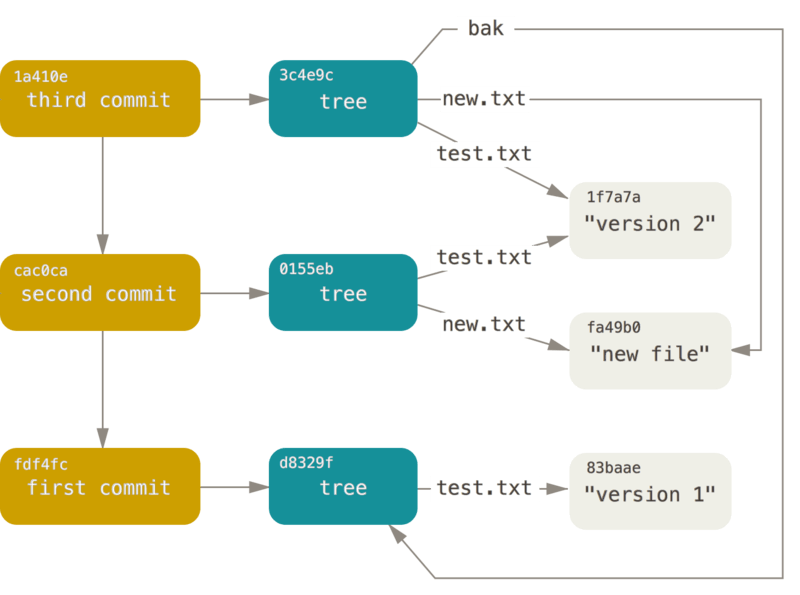
Git associates filenames to blobs using structures called trees, which store pointers to blobs and other trees. A commit is just a pointer to a specific tree. And a branch is basically a pointer to a commit.
This object database exists independently of commits and branches, because it is the thing that store the information about them. But what that means is that when you add a large file, even if it’s just to a side branch, you create a new entry in the object database for the rest of eternity.
Because the object database is independent of branches, so there's no real way to isolate your change. So everyone else who ever uses your repo will need to download your file changes, and that's why everyone is sad when you commit large files to Git.
What to do?
And yet the need exists: sometimes you do just need to move files between local and remote computers. If you're in this boat, your best options are:
- scp: the classic. Getting the syntax and filenames right can be a bit of a pain, but on the whole scp works very well for individual files.
- rsync: a better alternative, which does smart diffing if there are multiple files to transfer. This is what we use for Moonglow's file syncing.
Git-LFS is a separate, cool approach that doesn't quite solve this problem. You might know it because of Huggingface, which is basically Git-LFS-as-a-service.
Instead of storing large file contents as objects in the blob database, it store them in a cloud server that you set up, and puts a link to that in the blob database. This means the large file only gets pulled if it's needed. For repos that need to systematically store files that you expect everyone using the repo to need, Git-LFS is a very good option. But for one-off file syncs it's wasteful, as you'll still be adding a one-off file to a large, shared repo.
If you liked this, give Moonglow a try! It lets you start and stop GPUs instances on AWS and Runpod, and integrates with VSCode so that you can connect iPython notebooks to them without leaving your editor. We give you $5 of free GPU credit when you sign up.